3 母集団の要約と推定
平均値やOLSの結果は、計算に用いるデータによって異なります。 例えば、1947年に実施された第1回目の労働力調査と2025年に行われた調査では、平均賃金が大きく異なるでしょう。 これは1947年と2025年では、社会状況が大きく異なるので、当然の結果と考えられます。
では全く同じ社会を対象とした調査を、複数の研究チームが行った場合に、同じ平均賃金が算出されるでしょうか? もし同じ結果が得られないのでは、分析結果には、「客観性がなく信用できない」とも考えられます。 このような場合、分析結果をどのように受け取れば良いでしょうか?
以上の問題は、推定問題と呼ばれ、データ分析における中心的な課題の一つです。
Important到達目標
推定対象と推定結果を明確に区別する
- 推定対象と推定結果を定義するための概念: 母集団と抽出を理解する
推定対象を推論するツール、信頼区間を理解する
3.1 推定問題の枠組み
3.1.1 頻度論
推定問題を考える土台となる枠組みとしては、頻度論とベイズ論が有名です。 本ページでは、頻度論に基づく議論を紹介します。
まずは、以下の思考実験を考えてください。
Important 3.1: 思考実験
日本全国に、「2025年の日本の労働市場」を分析する研究チームが、大量に組織されました。各チームは同じ手順に基づき、平均賃金を計算します。ただしデータの収集は、各チームが独立して行います。
果たして、各チームは同じ結論にたどり着くでしょうか?
もし全てのチームが同じデータと同じコードを使えば、コーディング・ミスなどがない限り同じ結果になるはずです。 ところが、各チームが電話・ネット調査などでそれぞれが独自にデータを集めた場合、調査対象の対象となった回答者の違いから、得られるデータが異なり、結果も変わる可能性があります。
この思考実験の結果は、Chapter 2 で紹介した手法等を用いた推定結果の信頼性を「“否定”します」。 なぜならば、目の前にある推定結果は「誰にも再現できず」、この結果を信じる「合理的な根拠」がないためです。
この再現をめぐる問題について、「じゃんけん」を比喩として使ってさらに考えてみます。
Importantじゃんけんの比喩
いま、「1度じゃんけん勝負を行い勝った」とします。 この結果を根拠に、「自分は永遠に勝ち続ける」と結論づけることは妥当でしょうか?
大部分の人は、「負けることもあり得た中で、偶然勝っただけであり、もう一度やると結果が変わりそう」(結果を再現できないのではないか)と「想像」し、このような極端な結論を否定するのではないでしょうか?
データ分析についても同様であり、「同じ社会について、さまざまなデータが収集されうる中で、偶然手にしたデータから得られた推定結果であり、もう一度データを取り直すと結果が変わりそう」と考え、本章で紹介する信頼区間などを活用します。
言い換えると、Chapter 2 のようなデータから得られた(再現できない)計算結果を、「一般性のある結論」と見做すと、「じゃんけんに一回勝ったから、永遠に勝ち続けられると思いこむ」ことと同様の誤りを犯すことになります。
3.1.2 推定結果と推定目標
この思考実験の(ネガティブな)結果への対応策を議論するために、いくつかの理論的な概念が導入されます。
このような概念の中でも、特に次の2つを区別することが重要です:
推定結果(estimate):データから実際に計算される値
推定目標(parameter of interest/estimand):推定の対象となる“真の値”
たとえば、CPSSW04データから計算される平均所得は、あくまで「推定結果」であり、「全米の平均所得」という推定目標に近づくことを期待して計算されます。
推定結果と推定目標の関係性を明確にするために、母集団と抽出という概念を導入します。
3.2 母集団とサンプルリング
3.2.1 母集団
母集団 (Population) とは、推定の対象となる集団のことです。 Important 3.1 における母集団は「2025年の全世帯」、CPSSW04では、「2004年のアメリカの全世帯」が妥当な母集団でしょう。
3.2.1.1 母分布
母分布は、母集団における変数の分布です。 本ページでは、データに含まれる変数について、母集団全員を調査し、計算された分布であるとイメージしてください。
例えばCPSSW04の母集団である2004年のアメリカの全世帯が観察できれば、同年の 特定の \([\) 収入、学位、性別、年齢 \(]\) が、全人口に占める割合が計算できるはずです。
以下では、「分析者は母集団を直接観察できず、母分布を実際に計算することは不可能である」、という状況を想定します。 そして、直接知ることができない母分布やその特徴を、データから推定することを試みます。
3.2.2 推定目標の定義
本ページでは、母分布そのものではなく、母分布の特徴を推定する方法を紹介します。 推定の対象となる母分布の特徴を、推定目標と呼びます。 代表的なものとしては、母分布から計算された平均値およびOLSの結果があります。
3.2.2.1 母平均
データにおける分布と同様に、母分布からも平均値や条件付き平均値を計算できます。 このような母集団における平均値を、母平均と呼びます。
例えば、母集団における25才の平均所得は以下のように計算できます。
\[ 25才の条件付き母平均 \] \[ = 1\times 25才における「earningsが1」の条件付き母分布 \] \[ + 2\times 25才における「earningsが2」の条件付き母分布 \] \[ +... \]
3.2.2.2 Population OLS
本スライドでは、母分布から計算されるOLSの結果を推定目標とします。 このような推定目標を母集団におけるOLS推定値(Population OLS)と呼びます。
例えば、賃金と年齢の関係性を捉えるために、以下の母集団における平均二乗誤差を最小化する線型モデル (\(\beta_0 + \beta_1\times age\)) をPopulation OLSとして定義できます
\[ (25才の母平均 - (\beta_0+\beta_1\times 25))^2\times 25才の母分布 \] \[ + (26才の母平均 - (\beta_0+\beta_1\times 26))^2\times 26才の母分布 \] \[ +... \]
これらはすべて、実際には観察できない仮想的な計算結果です。 この結果をデータから推定することを目指します。
3.2.3 抽出
データは、何らかの方法で選ばれた事例の集まりであると想定します。 この事例を選ぶ過程を、抽出 (sampling) と呼びます。
母集団について推測するためには、データと母集団の関係について何らかの仮定を置く必要があります。 特に、母集団の事例をどれだけ偏りなくサンプリングできているのかは、分析の信頼性に大きく影響します。
最も重要な仮定は、ランダムサンプリングです。
Important 3.2: ランダムサンプルングの仮定
- データの各事例は、母集団から個別にランダムに選ばれている
本ページでは、分析に用いるデータはランダムサンプルングを満たすことを想定します。
3.2.4 推定結果と推定方法
推定結果(estimate)とは、データから計算される値のことです。 この推定結果は、推定対象(母集団上での真の値)に近い値であることが期待されます。
推定結果を計算する手順のことを、推定方法(estimator)と呼びます。
3.2.5 まとめ
本節で登場した重要な概念と仮定を整理すると、次のようになります。
Important母集団、抽出、推定対象、推定結果
母集団: 推定対象となる集団
- 推定対象: 母集団上で行いたい仮想的な計算
抽出: 母集団から事例を収集する手順
- ランダムサンプルングの仮定 (Important 3.2) : 事例は、母集団からランダムに選ばれている1
データ: サンプリングされた事例の集団
推定結果: データから計算される結果 (推定対象に近い値であることが期待される)
推定方法: データから推定結果を計算する具体的な計算方法
これらの関係は、以下の図にまとめられます:
図中の実線は、データの分析者が実際に観察・操作できる要素を、点線は想像上の操作や概念を表しています。 例えば、母集団から推定対象を計算する作業を、分析者が実際に行うことはできません。 なぜならば、母集団を直接観察することができないためです。
研究が直接確認できるものは、目の前のデータとそこから計算した推定結果のみです。 また研究者が具体的に行うことができる操作も、データを用いた推定結果の計算 (OLS等) のみです2。
3.3 推定方法
母平均やPopulation OLSは、以下の一般的な推定方法が利用できます3。
Important 3.3: 母平均やPopualtion OLSの推定
母集団上での仮想的な計算結果 として、推定対象を定義する
同じ計算をデータ上で行った結果を、推定結果とする
この推定方法は、以下の性質から正当化できます。
Important 3.4: 一致性
もしデータに代表性があり、かつ事例数が無限大であれば、データから算出したOLSの結果とPopulation OLSは一致する。
一致性からは、データが増えれば増えるほど、推定結果は推定目標に近づくことが期待できます。
ただし、この議論は「母集団において平均値やOLSの結果が計算できる」ということを、前提にしていることに注意してください。 例えば、母分布が「特殊な」場合、母平均が無限大になり、計算できない場合があります4。 またPopulation OLSについては、母集団において完全な多重共線性 が存在する場合、計算は不可能です。 そのため、多重共線性のない定式化を用いて、Population OLS を定義する必要があります。
3.3.1 一致性の限界
一致性は、推定方法 Important 3.3 を正当化する重要な性質です。 しかしながら、実際のデータ分析においては、それほど実用的な性質ではありません。 なぜならば、Population OLSとデータ上でのOLSが一致するためには、無限大の事例数 が必要となるからです。 いうまでもなく無限大の事例数を持つデータは存在しません。 言い換えると、実際のデータ分析では、推定結果と推定目標は”乖離している”と想定すべきです。
具体的な例から考えてみます。
library(tidyverse)
data("CPSSW04", package = "AER")
lm(earnings ~ age, CPSSW04)
Call:
lm(formula = earnings ~ age, data = CPSSW04)
Coefficients:
(Intercept) age
3.3242 0.4519 以上の結果は、データ上でのOLSでは、ageのパラメタは0.4519であることが確認できます。 一致性から、もしCPSSW04がランダムサンプルングの仮定を満たし、事例数が無限大であれば、「Population OLS におけるageのパラメタも0.4519である」という結論は必ず正しいものとなります。 ところが実際の事例数は、7986 であり、無限ではありません。 このため「Population OLS におけるageのパラメタも0.4519である」は、ほぼ間違った結論となります。
Importantポイント
ここまでの議論から、Important 3.1 の思考実験の結果は以下のように整理できます。
各研究チームは、ランダムサンプリングにより、データを集めたとする
データの事例数が無限大あれば、データから得られるOLSの結果は、常にPopulation OLSと一致する
- データから得られる推定結果は、どの研究チームでも同じ
現実的な事例数のもとでは、データから得られるOLSの結果は、常にPopulation OLSから乖離
- データから得られる推定結果は、研究チームよって異なる
3.4 信頼区間
3.4.1 統計的推論
「無限大のデータ」という非現実的な想定に頼らずに、正しい結論を示すことは可能でしょうか? データ分析においては、確実に正しい結論を示すことは、事実上不可能です。 このため多くのデータ分析では、ほぼ正しい結論を示すことを目指します。 このようなほぼ正しい結論を示すプロセスは、統計的推論と呼ばれます。
3.4.2 信頼区間
統計的推論に活用できるツールは、さまざまなものがありますが、中でも信頼区間が代表的です。
Important信頼区間
推定対象を一定の確率で含むと考えられる区間
推定対象を含む確率は、信頼確率と呼ばれ、研究者が指定する
手元にあるデータから計算される
Rにおいて、信頼区間を計算する方法は複数存在します。 例えばestimatrパッケージのlm_robust関数を用いれば、以下の仮定のもとで、信頼区間を計算します。
Important信頼区間計算の前提条件
データはランダムサンプルングされている
事例数は十分にある5
極端なハズレ値がない
例えば、以下のコードから、reformの平均値について95 \(\%\) 信頼区間を計算できます。
model <- estimatr::lm_robust(
earnings ~ age,
CPSSW04)
model Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper
(Intercept) 3.3241841 0.9657404 3.442109 5.801562e-04 1.4310807 5.2172874
age 0.4519313 0.0329688 13.707847 2.737848e-42 0.3873039 0.5165588
DF
(Intercept) 7984
age 7984以上の結果から、「Population OLSにおけるageは、概ね (95 \(\%\)) \(0.387\sim 0.517\) である」という主張を行うことができます。
3.4.3 信頼区間の解釈
本ページでは信頼区間の詳細な導出方法の説明は省略します。 代わりに信頼区間の解釈を詳細に紹介します。
\(95\%\) 信頼区間を活用する際に問題となるのは、 \(95\%\) の意味を正しく捉えることです。 そこで本節では、信頼確率について、いくつかの異なる、ただしすべて正当な解釈を紹介します6。
まずは 思考実験 Important 3.1 と最も密接な解釈である「繰り返し抽出」です。
Important解釈1. 多数の研究チーム
皆さんと他の研究チームは、同じ方法でデータを収集しますが、収集自体は独立して行い、データのシェア等も行いません。 このため、データの特徴は全てのチームで異なっており、計算される信頼区間も異なります。
これらの分析チームが各のデータから、95 \(\%\) 信頼区間を計算したとします。 もし信頼区間の仮定が全てのチームで満たされているならば、皆さんを含む大量のチームが計算した信頼区間のうち、95 \(\%\) は推定対象 (真の値)を含みます。
このような解釈は多くの教科書で紹介される標準的なものですが、歴史的に「わかりにくい」と批判されてきました。 特に社会・市場分析において、「同じ母集団を対象に研究する大量の分析チーム」が存在した現実の例を挙げることは困難であり、かなり抽象的な想像力が要求されます。
2つ目の解釈は「一人の研究者が長期間にわたって大量の研究を行う」という、より現実的な想像を土台に、信頼区間を”生産物”の品質管理として捉える解釈です。
Important解釈2. データ分析についての品質保証
これから皆さんは長期に渡って、さまざまな母集団 (社会) や研究目標について、多くのデータ分析を行なっていくとします。 これら全ての分析において、ランダムサンプリング等の仮定が満たされていることを前提に、95 \(\%\) 信頼区間を計算したとします。 当然さまざまな信頼区間が計算されますが、今後皆さんが計算する大量の信頼区間のうち、95 \(\%\) は推定対象を含むことができます。
このような品質保証のような見方を、信頼区間の提唱者であるネイマンは帰納的行動(Inductive Behavior)と呼びました。
最後に信頼区間は、仮説検定というアプローチと密接な関係があります。
Important解釈3. 検定の反転
今、ある推定対象 (例えば改装率)について、候補となる値がたくさん存在します。 この中から、明らかに推定対象ではないと値を除外していきます。 除外する方法は以下です。
仮にある値が推定対象の真の値 (例えば 1 \(\%\)) だと想定する
もしこの仮の値が、データ上での値とあまりにかけ離れている場合は、真の値の候補から除外する (この判断において、統計的検定を活用します)
全ての値について、1、2を繰り返し、除外されなかった値を信頼区間とする
つまりデータと大きく矛盾しない値の集合を信頼区間とします。
検定の反転を実際に行うためには、統計的検定の知識が必要です。 統計的検定については、本ページでは紹介しませんが、標準的な統計学・計量経済学の入門書では必ず紹介されているので、読んでみてください。
以上の解釈は、数学的には実は全て同じものであり、ストーリーが違うだけです。 各自が「一番しっくりくるもの」をとりあえずは選んで問題ありません
3.5 複雑すぎるモデルの問題点
モデルが複雑すぎると、推定において深刻な問題が生じることがあります。 複雑なモデルのパラメータを高い精度で推定するためには、十分な数の観測事例が必要になるためです。 このためデータ数が限られている場合、複雑なモデルを推定すると、推定精度が大幅に低下し、ミスリードな推定結果を導くおそれがあります。
ここでは、単純な数値例を用いてこの問題を確認してみます。
Important数値例
以下のような複雑な条件付き母平均を想定します7。
\[ E[Y\mid X] = X + 0.1\times X^2 + 2\times X^3 + 0.01\times X^4 + 5 \times X^5 \] \[ 0.1 \times X^6 + 3 \times X^7 + 0.1 \times X^8 + 0.1 \times X^9 + 0.1 \times X^{10} \tag{3.1}\]
条件付き母平均とこの想定に基づいてランダム・サンプルングされた50事例のデータを図示すると、以下のようになります。
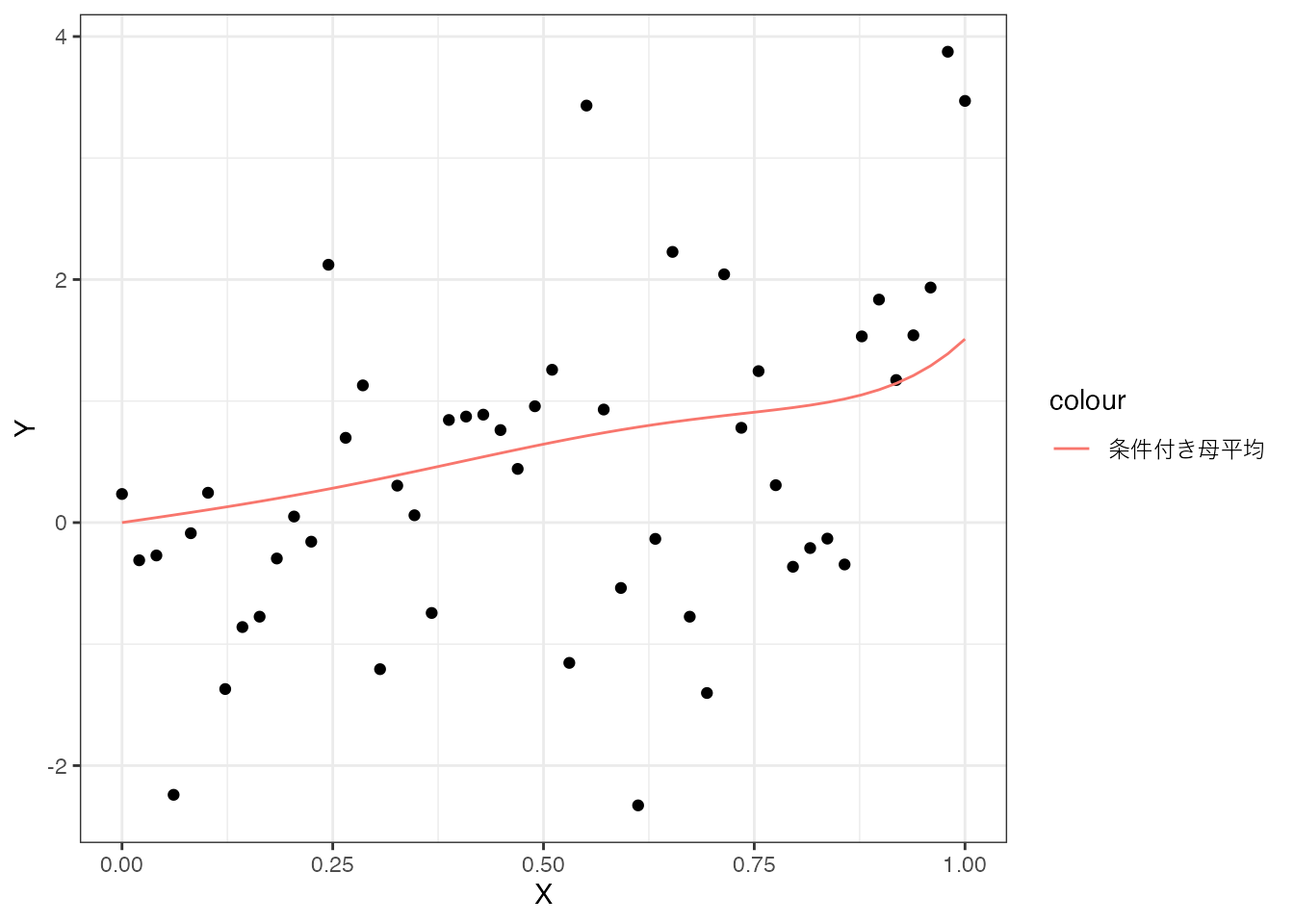
赤線が条件付き母平均、黒点がデータを表します。
まずは、単純な線型モデル \((\beta_0 + \beta_1\times X)\) を推定し、条件付き母平均を比較してみます。
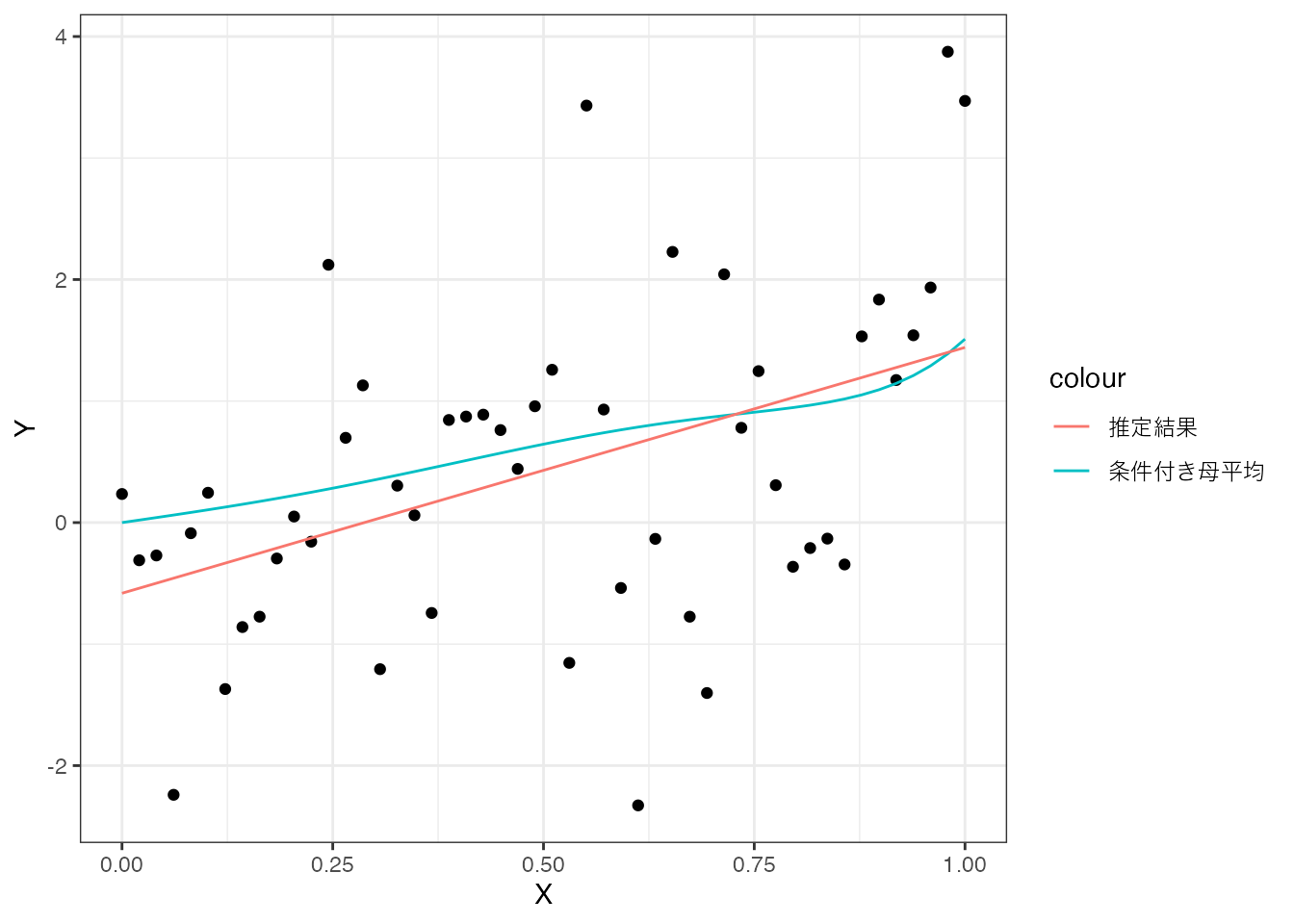
この図からわかるように、単純なモデルでは複雑な母平均を捉えることができず、推定結果と母平均に乖離が生じています。
次に、Equation 3.1 のような複雑な条件付き母平均を想定し、以下のような複雑なモデルを推定し、条件付き母平均を比較します。
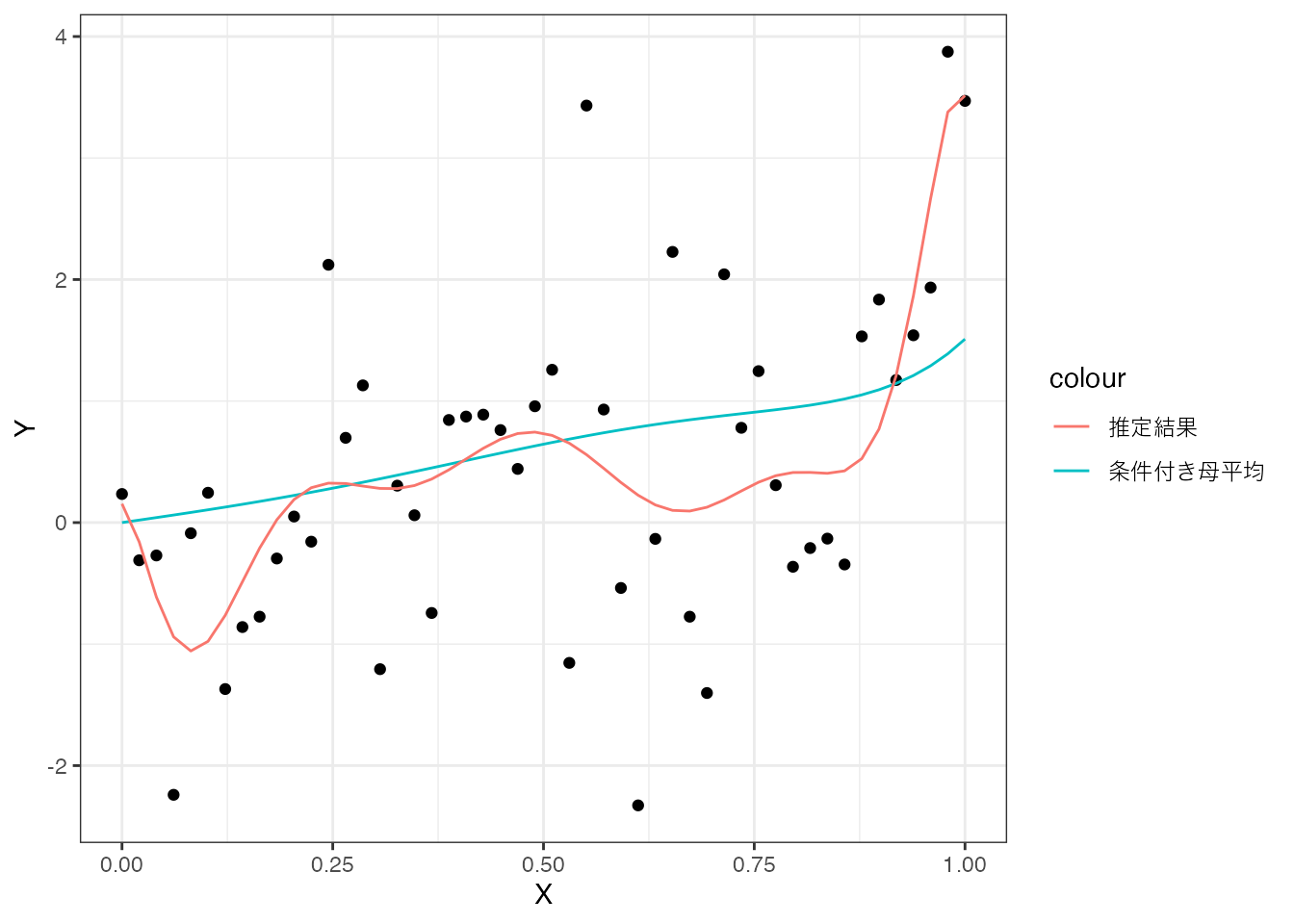
複雑なモデルの方が、条件付き母平均に近づくように思えるかもしれませんが、実際には母平均との乖離がむしろ拡大していることがわかります。 これは、少ないデータ(50事例)で複雑なモデルを推定したため、パラメータの推定精度が著しく低下したことを示しています。
では、同じ複雑なモデルを、十分なデータ(5万事例)で推定した場合はどうなるでしょうか。
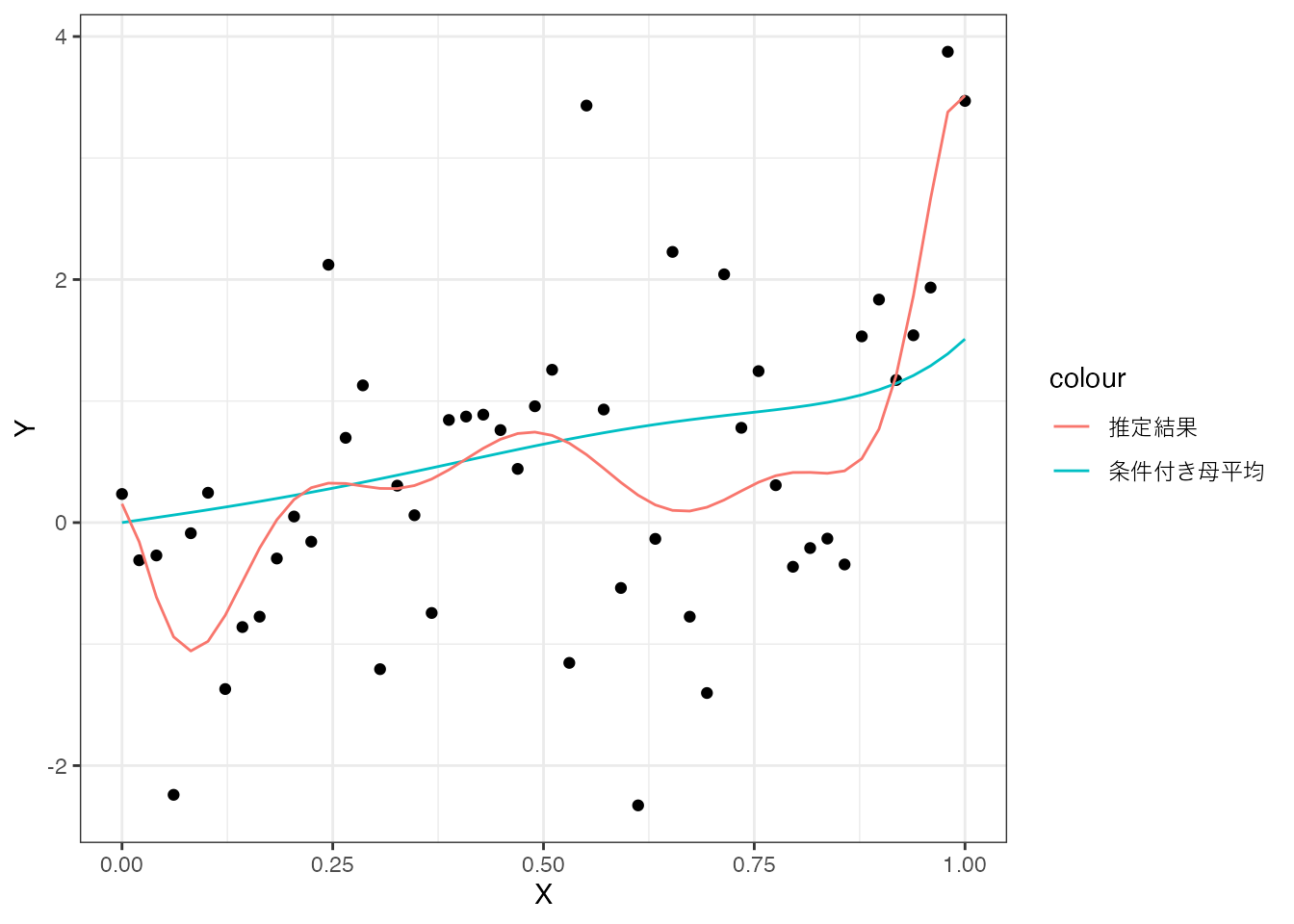
この場合、推定結果は条件付き母平均とほぼ一致しており、十分なデータがあれば、複雑なモデルでもOLSによって高精度な推定が可能であることが確認できます。
この数値例からわかるように、複雑なモデルを用いる際には、十分なデータがあるかどうかを慎重に検討する必要があります。
Hanley, James A. 2025. “Probabilistic Parameter Estimates That Require Less Small Print.” The American Statistician, no. just-accepted: 1–11.
厳密にはデータの事例が独立・無相関に選ばれている (Independent and Identically Distributed) を仮定しています。↩︎
実際のデータ分析では、OLSやベイズ法、機械学習による推定だけでなく、データの前処理も研究者が行うべき重要な操作となります。↩︎
アナログ原理やプラグイン原理として呼ばれています。↩︎
母平均が計算できないケースとしては、母分布がコーシー分布である場合などが有名です。↩︎
どのくらいあれば十分なのかは、難しい問題です。ただし多くの教科書では、200事例以上が基準とされています。↩︎
個々の \(Y\) と \(X\) の値は、以下で決定されます: \(X=\) 0から1までの一様分布、 \[ Y=E[Y\mid X] + \underbrace{u}_{平均0、分散1の正規分布} \] ↩︎