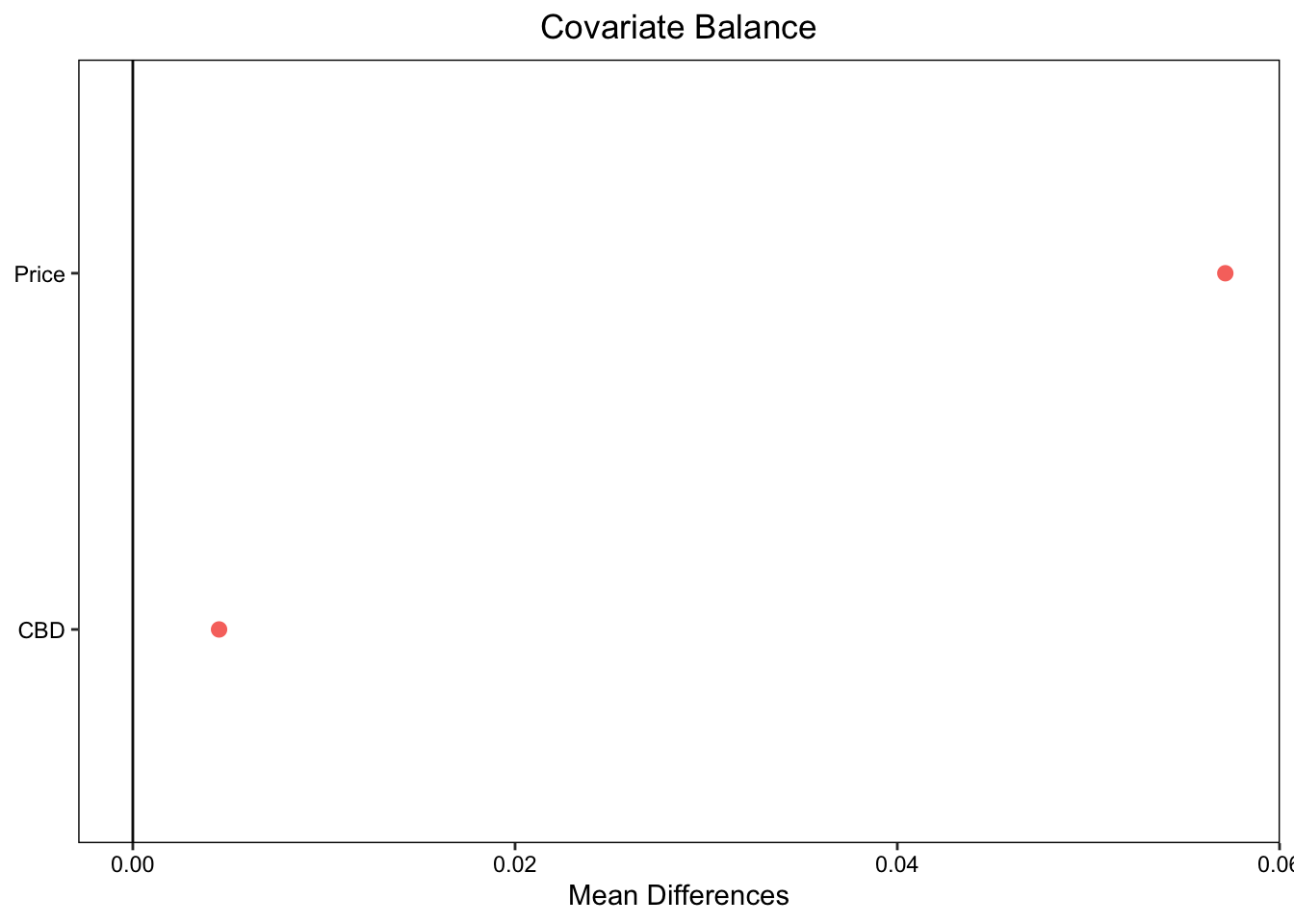
5 把握を目的とする要約: バランス後の比較
バランス後の比較では、\(D\)間での\(X\)についての格差が解消された場合の、\(Y\)についての差の推定を目指します。 このような比較は、因果効果や格差の推定の肝となります。 詳細な入門としては、Chattopadhyay and Zubizarreta (2024) などを参考にしてください。
5.1 実例
5.1.1 不動産市場の年次比較
例えば、2022年と2021年の東京23区の中古マンション市場における、取引価格と立地(中心6区かそれ以外か)について平均的な差は以下の通りです。
2022年においては、平均取引価格が2021年に比べて上昇していますが、同時に中心6区の物件割合も増加しています。 一般に中心6区の物件の方が取引価格が高い傾向が予想されるので、その分取引価格の上昇が”底上げ”されている可能性があります。 もし中心6区の物件割合が不変であった場合、平均取引価格にどのような差が残るでしょうか?
このような問いに対して、バランス後の比較分析は回答できます。
5.1.2 合計特殊出生率
合計特殊出生率の国家間/時代間比較は、バランス後の比較の代表例です。 出生数の動向を把握する上で、新生児数を年次や国家間比較は、有益だとみなされてきました。 合計特殊出生率 は、成人の年齢構造の違いをバランスさせるために利用されている指標です。 単純な出生率(一年間に生まれた子供の数/女性の数)は、成人の年齢構造の影響を強く受ける可能性があります。 比較的高齢の成人の比率が高まれば、出生率は低下することが予想されるからです。 対して合計特殊出生率は、「仮に年齢構造が同じであった場合」の出生率を、以下の方法で推定しています \[\frac{15歳の女性が産んだ子供の数}{15歳の女性の数} +..+ \frac{49歳の女性が産んだ子供の数}{49歳の女性の数}\]
シンプルな枠組みであり、大規模なデータが活用可能な状況では、有効だと考えられます。 一方で、年齢以外の属性(教育歴、居住地等々)もバランスさせる場合、同じ属性を持つ事例数が少なくなり、適用が難しくなります。
5.1.3 既存店ベースの比較
バランス後の比較は、企業の経営戦略を考える上でも用いられます。 小売や飲食/宿泊業などでは、しばしば既存店に絞った上での、売上比較がなされます。 例えば、あるコンビニチェーンで、店舗あたりの平均売り上げが1000万円増大したとします。 同時に去年から今年にかけて、新規出店も大きく増加したとします。 新規店の方が売上が高くなる傾向がある場合、新規店割合の違いが、平均売上の上昇をもたらした可能性があります。
既存店割合をバランスさせるシンプルな方法として、既存店のみに絞った平均売上を比較がよく行われます。 合計特殊出生率と同様に、新規店比率のみをバランスさせるのであれば、非常に実践的な方法です。 しかしながら他の属性、例えば客層の変化などもバランスさせたい場合は、事例数が不足する可能性が高くなります。
5.2 推定対象
5.2.1 バランス後の平均値
以上の推定対象は、一般に以下のように定義できます。
グループ \(d\) における \(Y\) の平均値は、一般に以下のように書き換えることができます。 \[(d)におけるYの平均値\] \[=\Biggr\{(X=x\ \&\ d)におけるYの平均値\times (d)における(X=x)の割合\Biggr\}\] \[のxについての総和\]
\(D\) 間での平均差を生み出す要因は、以下に分解できます。
\(D\) の間での\(Y\)の平均値の違い
\(D\) の間での\(X\) の分布の違い
バランス後の比較における推定対象は、\(X\) の分布の違いを排除したバランス後の平均値の差として定義します。 \(d\)のバランス後の平均値は、\[(d)におけるYのバランス後平均値\] \[=\Biggr\{(X=x\ \&\ d)におけるYの平均値\times (X=x)へのウェイト\Biggr\}\] \[のxについての総和\] バランス後の平均値の差は、\(X\) 内での平均差の\((X=x)へのウェイト\)を用いた集計値として書き換えることができます: \[\Biggr\{\Bigr[(X=x\ \&\ D=1)におけるYの平均値-(X=x\ \&\ D=0)におけるYの平均値\Bigr]\] \[\times (X=x)へのウェイト\Biggr\}のxについての総和\]
\((X=x)へのウェイト\)は、原理的には研究者が設定できます。 以下、最も代表的なウェイトである、母集団全体での\(X=x\)の割合をウェイトとして、バランス後の平均値の推定を目指します。 因果推論においては、母集団全体での割合を用いた集計値を平均効果と呼んでおります。
5.2.1.1 実例
例えば、立地と取引年ごとの平均取引価格は以下です。
| 平均価格 | CBD | TradeYear | 事例割合 |
|---|---|---|---|
| 37.7 | 0 | 2021 | 0.41 |
| 60.5 | 1 | 2021 | 0.11 |
| 39.2 | 0 | 2022 | 0.37 |
| 64.8 | 1 | 2022 | 0.11 |
2022/2021年の平均取引価格差は、データ全体では2.2 ですが、\(CBD=1\) では \(64.8 - 60.5 =\) 4.3、\(CBD=0\) では \(39.2 - 37.7=\) 1.4 となります。 よって立地をバランスさせた後の平均差は4.3 と 1.4 の”平均値”となります。 例えばデータ上での立地の割合、 CBD=1について0.22、CBD=0について0.78、をウェイトとして用いるのであれば 2 がバランス後の平均差となります。
5.2.2 Balancing Weight
バランス後の平均値は、Balancing weightを用いた加重平均としても計算できます。 バランス後の平均値を以下のように書き換えられることで、Balancing weight \(\omega(x)\) は定義できます。
バランス後の平均値 \[(d)におけるYのバランス後平均値=\Biggr\{(X=x\ \&\ d)におけるYの平均値\] \[\times \underbrace{\frac{(X=x)へのウェイト}{(d)における(X=x)の割合}}_{\equiv\omega(d,x)}\times (d)における(X=x)の割合\Biggr\}\] \[のxについての総和\]
バランス後の平均値は、\(D_i=d\)を満たす事例についての加重平均としても算出できます。 \[\frac{D=1の事例についての\omega(d)\times Yの総和}{D=1を満たす事例数}\] ただし\(N\)は全体の事例数、\(I(D_i=d)\)は事例\(i\)の\(D\)の値が\(d\)であれば1、それ以外であれば0となる変数です。よって\(D_i=d\)を満たす事例について、Balancing weightsを掛けたものの総和を計算し、\(D_i=d\)を満たす事例数で割ることで計算できます。
例えば、\((X=x)へのウェイト\)としてCBD=1が0.22、CBD=0が0.78を用いるのであれば、Balancing Weightは以下のように算出できます。
| 平均価格 | CBD | TradeYear | 事例割合 | Balancing Weight |
|---|---|---|---|---|
| 37.7 | 0 | 2021 | 0.41 | 1.90 |
| 60.5 | 1 | 2021 | 0.11 | 2.00 |
| 39.2 | 0 | 2022 | 0.37 | 2.11 |
| 64.8 | 1 | 2022 | 0.11 | 2.00 |
5.2.3 仮定: Overlap
母集団全体での\(X=x\)の割合をウェイトとした、バランス後の平均値を推定対象とするためには、母集団に対して以下を推定する必要があります。
Important
Positivityの仮定
- 全ての\(X\)の組み合わせについて、\(D=1\)の事例も\(D=0\)の事例も、母集団上には両方存在する: \[1 > E[D|X] >0\] ただし \(E[D|X]\) は\(D\)の母平均(\(D=1\)の割合)
Positivityが成り立っていない、母集団上で\(D=1\) または \(D=0\) しか存在しない\(X\)の組み合わせが存在する、場合バランス後の比較は根本的に不可能です。 例えば、教育経験\((=X)\)をバランスさせた男女間\((=D)\)での賃金格差を推定したいとします。 ここで関心となる母集団は、男女間での教育経験の分断が極めて大きく、大学卒以上の女性は存在しないとします。 この場合、大学卒の女性割合は\(0\)であり、どのようなBalancing weight \(\omega(大学卒)\) を用いたとしても、男性/女性の大学卒比率を揃えることは不可能です。 言い換えるならば、大学卒の女性が存在しないため、大学卒内で男女間の賃金を比較できないため、バランス後の比較は不可能です。
@(有限標本ではOK?)
((では?)、Positivityの不成立についての対処を論じます)
5.3 推定方法
\(X\)の組み合わせの種類に比べて、十分な事例数が存在するのであれば、Balancing weightは、データ上での\(X\)の割合を用いて計算できます。 この方法はExact Matchingとして知られる方法による推定結果と完全に一致します。 Exact Matchingは、例えばMatchIt package (Stuart et al. 2011) などを利用して実装できます。
しかしながら \(X\) の組み合わせが増えると、実行不可能です。 例えば\(X\)に、両親の年収や資産などの連続変数が含まれている場合は、\(X\)の組み合わせが非常に大きくなり、Balancing weightsを計算することは事実上不可能です。
この問題を解決するために、次節以降で紹介する、OLSや傾向スコアの逆数などが有用です。
5.4 Rによる実践例
以下のパッケージを使用
readr (tidyverseに同梱): データの読み込み
matchit: Exact matchingを含む多様なMatchingを実装
5.4.1 準備
データを取得します。 \(D\) として、中心6区かそれ以外で、1/0となる変数を定義します。 シンプルな比較分析について信頼区間は、データ分割は不要です。
Data = readr::read_csv("Public.csv") # データ読み込み
Data = mutate(
Data,
D = if_else(
LargeDistrict == "中心6区",1,0
)
)5.4.2 Balanced Weight
MatchItパッケージ内のmatchti関数を用いて、Balanced weightsを計算します。 例えば立地別の平均取引価格とその信頼区間は、以下で計算できます。
Match = MatchIt::matchit(
D ~ Size + Tenure + StationDistance, # D ~ Xを指定
Data, # 用いるデータの指定
method = "exact", # Balanced weightを計算するために、exact matchingを実行
target = "ATE" # サンプル全体のXの分布をターゲット
)
DataWeight = MatchIt::match.data(
Match,
drop.unmatched = FALSE # Balance weightが計算できない事例も含む
) # Balance weightを含んだデータを生成
Match # Balance weightの特徴を表示A matchit object
- method: Exact matching
- number of obs.: 6378 (original), 1702 (matched)
- target estimand: ATT
- covariates: Size, Tenure, StationDistancenumber of obs.において、元々の事例数 (6378) と balanced weightを計算できた事例数 (1702) を表示しています。 事例が大きく減少しており、balanced weightを計算できない事例が多かったことを示しています。 この理由は、Size, Tenure, StationDistanceが完全に一致する事例が、\(D=1\) または \(D=0\) のどちらかしか存在しない場合が多いためです。
Balanced weightが算出できた事例について、バランス後の平均差を計算すると以下となります。
lm(Price ~ D,
DataWeight,
weights = weights # Balancing weightsを使用
)
Call:
lm(formula = Price ~ D, data = DataWeight, weights = weights)
Coefficients:
(Intercept) D
36.05 12.55 単純比較の結果は以下であり、大きく異なることが確認できます。
lm(Price ~ D,
DataWeight)
Call:
lm(formula = Price ~ D, data = DataWeight)
Coefficients:
(Intercept) D
38.04 20.94 ただし今回のように、多くの事例が分析から除外されてしまった場合、単純比較とバランス後の平均差が乖離する理由は不明瞭です。 \(X\)をバランスさせることで平均差が変化した可能性がありますが、分析事例の限定も値を変化させます。 このため次節以降の方法を用いて、極力分析事例を除外しない方法を用いることが望ましいです。
5.5 Reference
Chattopadhyay, Ambarish, and José R. Zubizarreta. 2024. “Causation, Comparison, and Regression.” Harvard Data Science Review 6 (1).
Stuart, Elizabeth A, Gary King, Kosuke Imai, and Daniel Ho. 2011. “MatchIt: Nonparametric Preprocessing for Parametric Causal Inference.” Journal of Statistical Software.