| Price | Size | TradeYear | LargeDistrict | Tenure |
|---|---|---|---|---|
| 200 | 105 | 2022 | 中心6区 | 31 |
2 要約の基本コンセプト
2.1 観察できない変数が引き起こす問題
データから観察できない変数の存在は、あらゆる事例分析の最も深刻な問題の一つです。 このような変数への対処について、膨大な議論が蓄積されています。
観察できない変数がもたらす問題は、個別事例分析において特に顕著です。 以下では、取引価格(Price; 単位 \(=\) 100万円) \(=Y\) と物件の特徴 \(=X\) の関係性を把握するために、個別事例を丹念に見ていきます。 例えば、以下の2億円で取引されている物件が、データの中に含まれていました。
この事例から、部屋の広さが105平米で中心6区(港、中央、千代田、新宿、渋谷、文教)に立地する物件は、2億円で取引される傾向があったと結論づけても良いでしょうか? ほとんどの応用でこのような推測は、不適切です。 実際に同じデータの中に、取引価格以外全く同じ特徴を持つ物件の取引事例が、以下の3件ありました。 これらの事例と比較すると、2億円はかなり高い価格での取引だったことがわかります。
| Price | Size | TradeYear | LargeDistrict | Tenure |
|---|---|---|---|---|
| 200 | 105 | 2022 | 中心6区 | 31 |
| 150 | 105 | 2022 | 中心6区 | 33 |
| 92 | 105 | 2022 | 中心6区 | 21 |
| 110 | 105 | 2022 | 中心6区 | 30 |
なぜこのような取引価格のブレが生じるのでしょうか? データの誤入力など潜在的な理由は複数ありますが、有力なのはこのデータに含まれない重要な変数 が存在することです。 例えば、最寄駅や公園の近くにあるか否かなどのより詳細な立地情報が考えられます。 あるいは売り手や買い手の”交渉力”を反映している可能性もあります。 このような多様な要因が、取引価格に影響を与え、結果として事例の下振れ/上振れが生じます。
観察できない変数は不動産のみならず、労働者や家計、企業、あるいは国レベルの分析でも同様の問題を引き起こします。 観察できる変数 \(X\) が一致した事例内でも、観察できない変数は事例間で大きく異なっている可能性が高く、結果 \(Y\) の値に大きな差が生まれます。 そして現実の社会や市場の複雑さを考慮すると、どれだけ詳細な調査(含むインタビュー調査や参与観察)を行ったとしても、\(Y\)に影響を与える全ての要因を観察することは困難です。
2.1.1 コンセプト: 集計
先の個別事例分析では、観察できない変数の偏りを確認する方法として、同じ\(X\)を持つ事例と比較しました。 このようなアプローチの発展として、同じ\(X\)を持つ事例集団について、\(Y\)の特徴を要約する方法があります。 例えば、平均値や分散、中央値、あるいは研究者による”所見”や”印象”、代表的な事例を紹介するなどです。
恣意性の影響を緩和するために、調査計画を立てる時点で、要約方法も決定し、分析を通じてコミットすることが望まれます。 代表的な値の候補としては、中央値や最頻値など多くの候補があります。 現状よく用いられるのは、平均値の活用です。
以下では、価格 (Price) と広さ (Size)、立地 (中心6区/その他)、取引年 (2021/2022)について、データに含まれる事例の分布をHeat mapで図示しています。
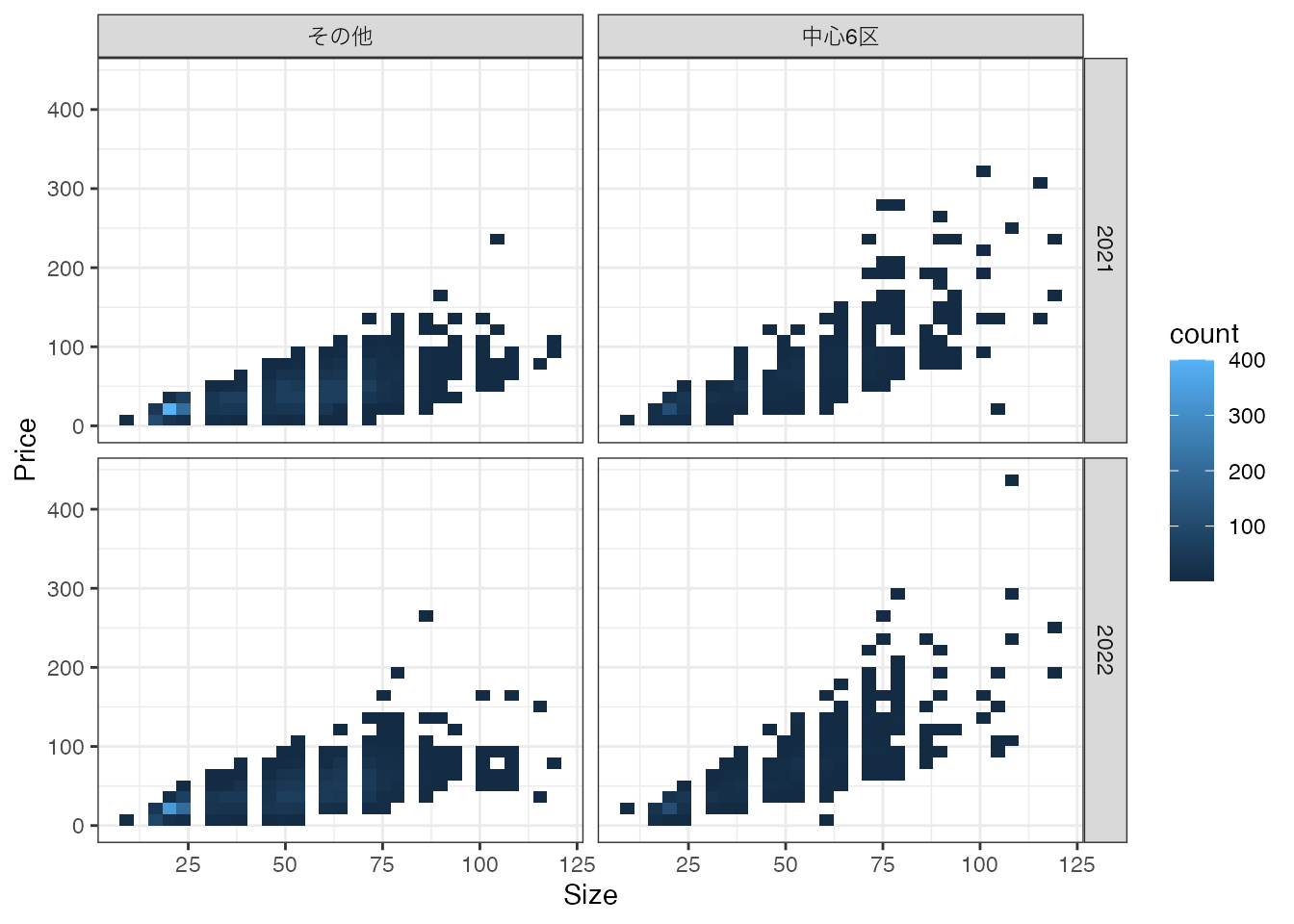
上記の散布図は、社会分析に用いるデータの持つ典型的な特徴を表しています。 極めて乱雑であり、同じ\(X\) でも \(Y\) が異なる事例が多くなっています。 これは、観察できない変数の偏りが深刻である可能性を示唆しています。 また \(X\) の値に応じた事例数の偏りも顕著であり、特に100平米を超えるような物件の取引事例は少なくなっています。
以下の各点は、各\(X\)の組み合わせごとに計算された平均値を図示しています。
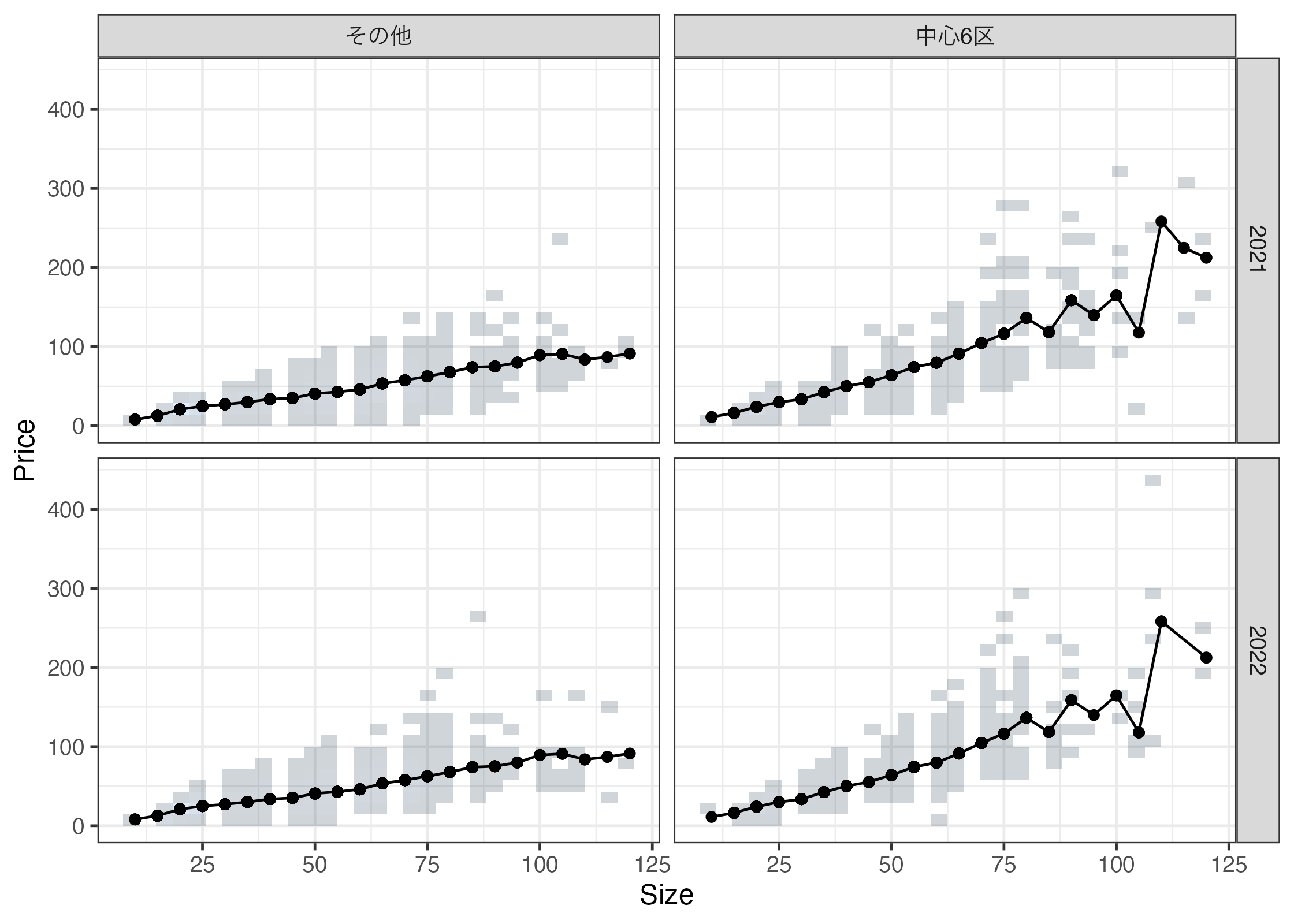
同図からは、\(Y\) と \(X\) のデータ上の関係性について、いくつか示唆を与えてます。 部屋が広くなると取引価格は高くなる傾向があり、この傾向は中心6区で特に顕著となります。
しかしながら多くの応用では、このような\(X\)ごとに集計するだけでは、不十分です。 特に以下の問題に注意が必要です。
2.1.2 集計の注意点
2.1.2.1 少数事例の集計
平均値は有力な要約方法ですが、算出に使用する事例の数に注意してください。 Figure 2.1 では、特に100平米を超える物件について少なくなっています。仮に平均値を計算するとしても、事例数が少ないと、各事例の観察できない変数の偏りの影響を強く受ける可能性があります。 この問題については、Section 2.2 で議論します。
2.1.2.2 分析に含まれていない変数の問題
\(Y\) 以外の変数についても、\(X\) 間で異なることに常に注意を払ってください。 Figure 2.1 がとらえる取引年、立地、部屋の広さと価格の関係性を解釈する際には、注意が必要です。 同図は、Sizeが増えると平均取引価格が上昇する傾向を示しますが、同時に築年数なども異なる可能性があります。 実際に築年数について、平均値を計算すると以下のようになりました。
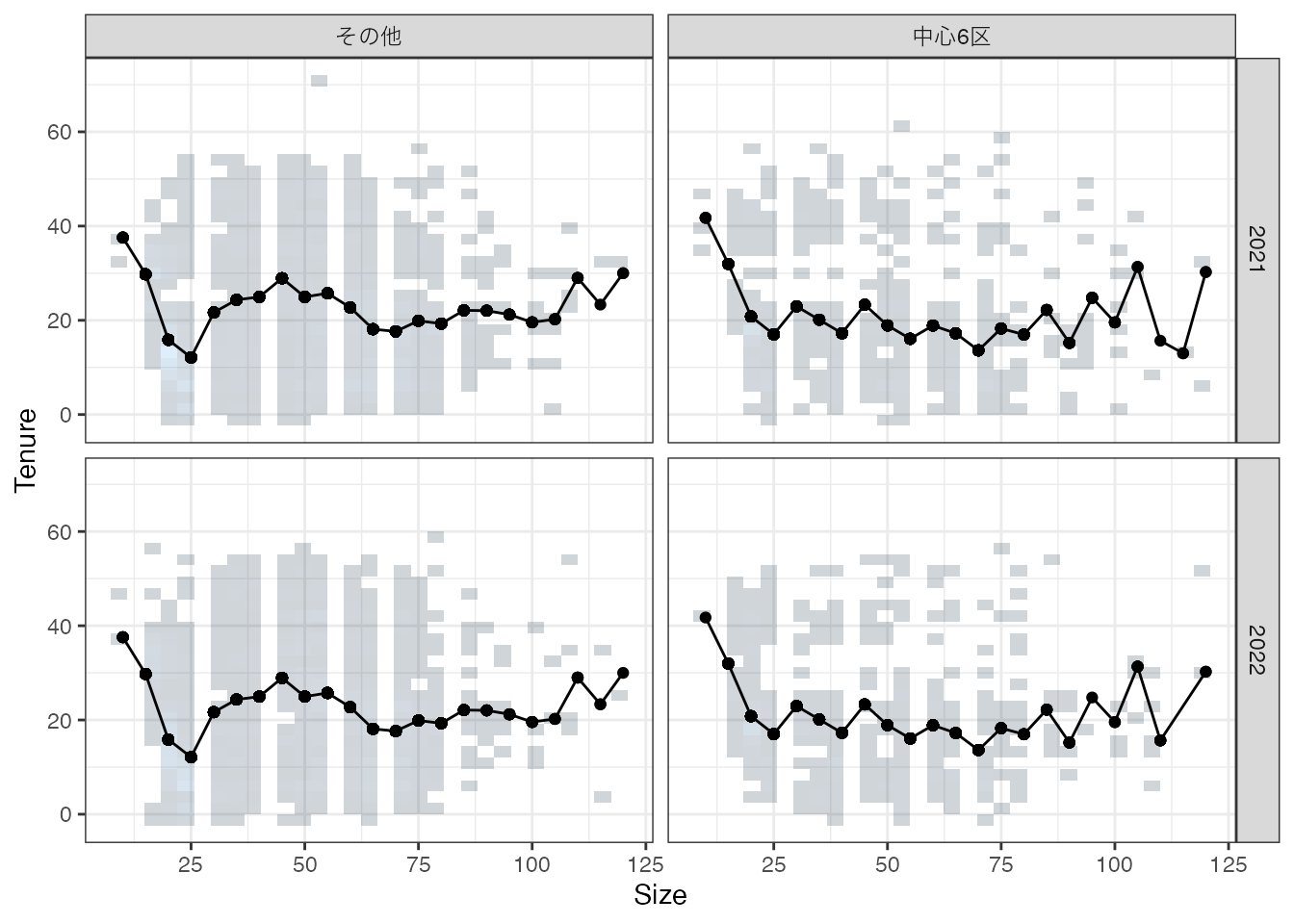
Size間で見られる取引価格の違いは、このような築年数の違いによっても、生じている可能性があります。 このような観察できる変数の違いについての対処は、Chapter 5 で議論します。
観察できない変数の違いも取引価格に違いを与える可能性があります。 この問題については、万能の解決策は存在しません。 統計的因果推論などで、膨大な議論が存在ます。
2.2 観察できない事例が引き起こす問題
少数事例の集計が引き起こす問題を正確に理解するために、頻度論と呼ばれる枠組みを導入します1。 具体的なイメージを持つために、「自分と同じ課題に取り組む他の研究者達」を想像してください。 この研究者は、あなたと同じ社会を対象に同じ手法を用いて分析しています。 ただしデータは、独立して収集しているとします。 このような研究者達は、あなたと同じ分析結果に到達するでしょうか?
簡単な理科の実験であれば、実験の手続きが同じであれば、誰がやっても同い結論に到達します。 例えば水の沸騰温度については、水に不純物を入れないなどを守れば、誰がやっても100度で沸騰します。 このため”科学的事実”に合意することが容易です。
対して現実社会における多くの現象については、独立した研究者は、同じ結論に到達することは困難です。 なぜならば、分析に用いる事例が異なるためです。 ほとんどの応用で、独立して収集したデータが、完全に一致する可能性は無視できるほど小さくなるでしょう。 すなわちある研究者が観察した事例を、別の研究者は観察できない可能性が高いのです。
分析結果の不一致の典型例としては、報道機関による世論調査が挙げられます。 複数の調査結果が、毎月公開されていますが、その結果は各社で異なっています。 理由は複数考えられますが、最も単純なものは、調査対象となる回答者が異なるためです。 典型的な世論調査では、各社が独立して電話番号をランダムに発生させるなどの方法で、1000-2000名ほどの回答者を極力ランダムに選んでいます。 しかしながら、異なる調査に同じ人が回答する確率は、非常に低くなります。
観察できない事例の存在は、データにおける観察できない変数の偏りをもたらします。 ある研究者には、偶然、公園に近い物件の取引事例ばかり集まってくるかもしれません。 このような研究者のデータで計算された取引価格の平均値は、他の研究者と比べて、上振れる可能性が高いです。 すなわち要約した値であったとしても、研究者間で同じ値に合意できなくなります。
事例研究において、人々が同じ結果を観察できない、という問題は深刻です。 なぜならば、「独立した個人や組織が同じ結果を観察できるので推定結果を事実として認定する」、という強力な枠組みが活用できません。 この問題に対処するためには、何らかの概念的な枠組みが必要となります。
2.2.1 コンセプト: 母分布とサンプリング
観察できない事例の問題と、それに伴う分析結果の不一致の問題を適切に論じるために、母分布という分析概念を導入します。 母集団を導入することで、共通の正答と各々のデータから得られる回答が、分離して定義できます。
「私たちが手にしているデータは、母集団という無数の事例の集団から、選ばれた事例から構成されている」と 想定 します。 さらに本ノートでは、事例は完全ランダムに選ばれていると仮定します。 このような仮定をランダムサンプリングと呼ばれます。
私たちが得られる回答は、このランダムに選ばれた一部の事例のみから得たものであり、正答とは一致しません。
例えば日本全体のすべての家計が母集団であり、母集団における夫婦間の平均的な家事分担を知りたいとします。 この場合、正答はすべての家計を調査し尽くせば得ることができます。 対して私たちのデータは、家計全体の一部であり、そこから得られる回答(例えば、データ上の平均的な分担)は、母集団における正答とは異なります。 極端な場合として、日本全体では妻の方が夫よりも家事負担が大きかったとしても、データに含まれる事例が偶然偏り、回答としては夫の家事負担がより大きいという結果を得る可能性があります。
母集団として、仮想的な集団を想定することもできます。 例えば、あるコンビニのレジデータに、ある日の全ての来客者について、購入金額が全て記録されているとします。 この場合、現実の来客者全てが記録されているため、母集団は存在しないと考えることも可能です。 一方で、その日にコンビニを訪れた顧客は、潜在的な顧客の一部であると想定することもできます。 皆さんも、よく利用するコンビニであったとしても、毎日利用しないのではないでしょうか? この場合の母集団は、潜在的な顧客となります。
母集団を想定すると、母集団における変数の分布も定義できます。 例えば、「取引物件の母集団において、中心6区に立地する物件の割合は2割」、といった感じです。 また母分布を定義できれば、そこから母集団における平均値(母平均)も定義できます。 平均値の推定を目指す研究であれば、この母平均が正答となります。 例えば、「中心6区に立地する50平米の中古マンションの2022年における平均取引価格は5000万円」、といった感じです。
何を正答するかは、推定対象、ひいては活用したい意思決定問題に応じて、人間が適切に設定する必要があります。 本ノートは、多くの予測/社会の把握を目的とした分析において、母平均は正答となることを論じます。 同時に、データから回答を得る方法は、目的に応じて大きく異なることも強調します。
注意が必要なのは、「我々には母分布や母平均を正確に知ることは不可能である」ことがデータ分析法の前提である点です。 知ることができない母分布や母平均を、手元にある限られたデータから、以下に推測するのかが、データ分析の中心的な挑戦となります。 データが母集団の一部であり、観察できていない事例が存在する以上、データ上の平均値と母平均は一致しません。 またデータはランダムに選ばれているので、独立した研究者間で、平均値について厳密な合意はできません。
2.3 数値例
以上の概念を明確にするために、簡単な数値実験を行います。 今、4名の研究者が独立して20事例を集めたとします。 各事例について、取引価格 \(Y\) と 部屋の広さ \(X\) がデータから観察できるとします
母分布は以下のように設定しています。
部屋の広さは、\(X\in\{30,35,40,..,80\}\) が同じ割合で存在
取引価格は、
立地が中心6区ではなく部屋の広さが75以下であれば \[50 + 0.1 \times X + 0.001 \times Size^2\]
立地が中心6区、または、部屋の広さが75以上であれば \[55 + 0.1 \times X + 0.001 \times Size^2\]
立地が中心6区、かつ、部屋の広さが75以上であれば \[60 + 0.1 \times X + 0.001 \times Size^2\]
以下の図は、4名の研究者が手にするデータと平均値を図示しています。
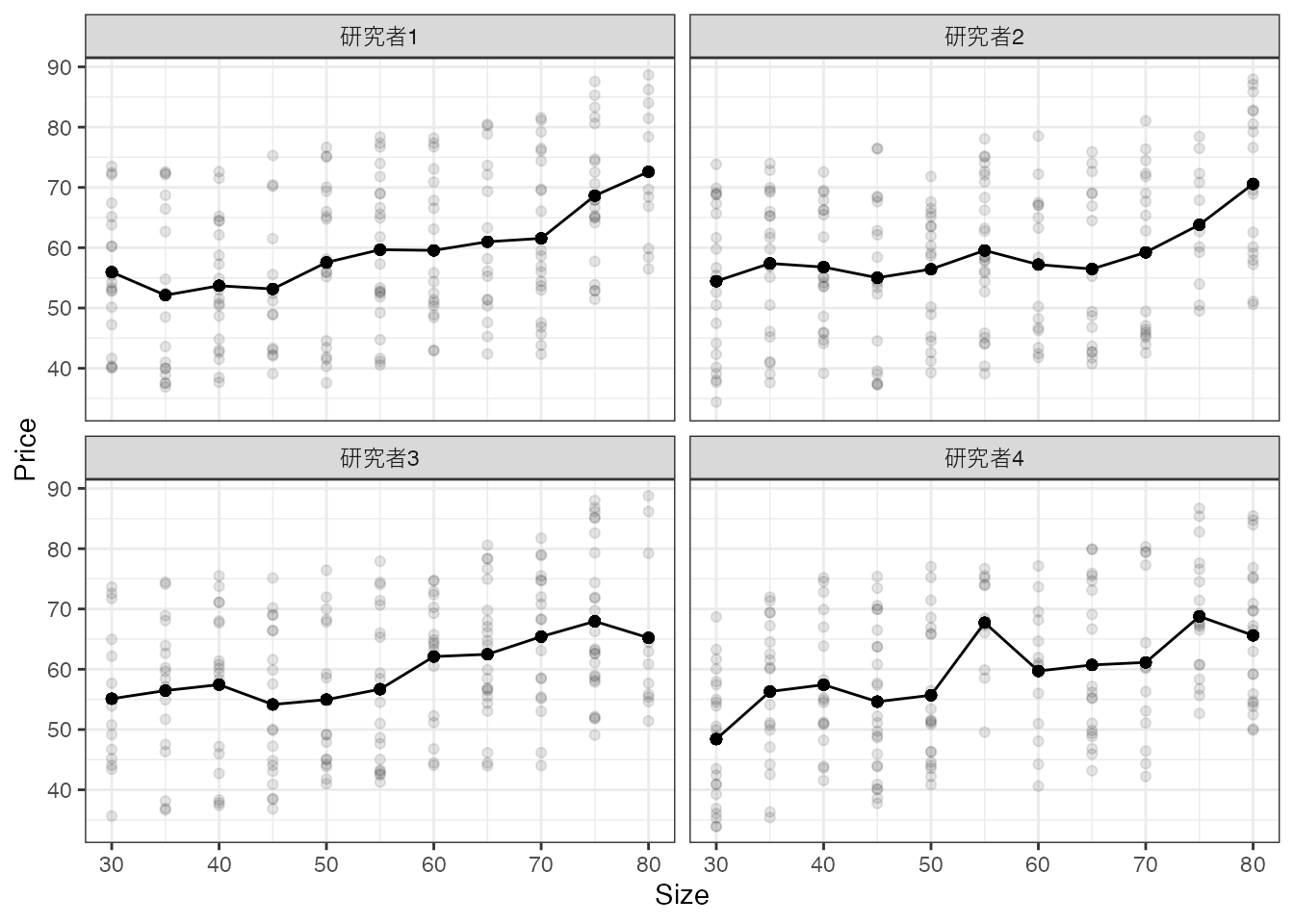
平均値について、研究者間で大きな違いが見られます。
この図に母平均を上書きすると以下のようになります。 ただし図を簡略化するために、各事例の値は排除します。
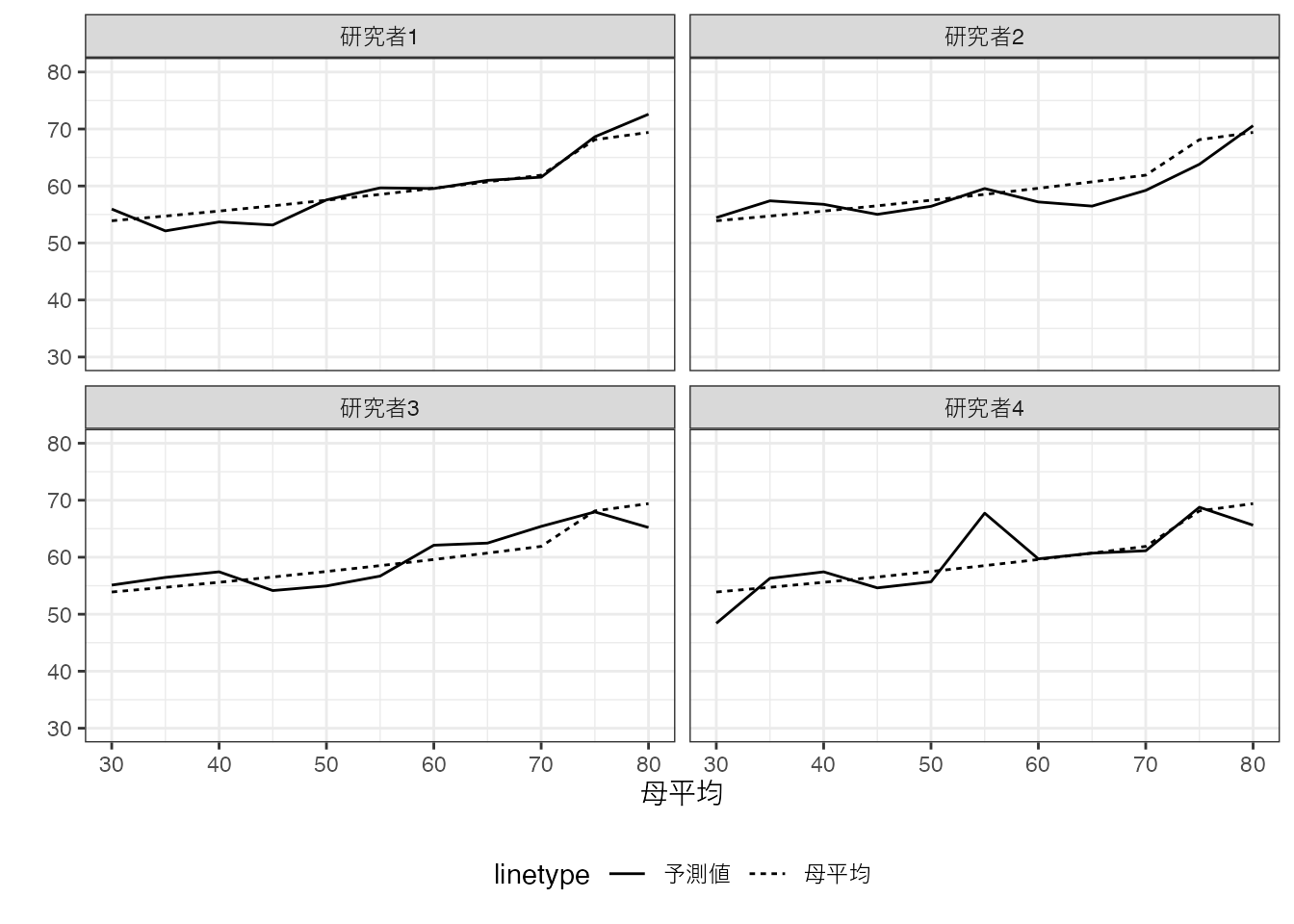
重要な点として、母平均とデータ上の平均は乖離していることを確認してください。 また乖離の仕方は、研究者によって異なります。 言い換えるならば、母平均は全員共通である一方で、データ上の平均値は異なっています。
2.4 Reference
Lin, Hanti. 2024. “To Be a Frequentist or Bayesian? Five Positions in a Spectrum.” Harvard Data Science Review 6 (3).
頻度論以外にはベイズ法と呼ばれる枠組みもあります。Lin (2024)などを参照ください。↩︎